Анализировать поведение поисковых роботов вебмастера еще не привыкли: при продвижении сайтов многие специалисты до сих пор полагаются исключительно на архаичные, а порой и бесполезные методы борьбы за положение в органической выдаче. Но на деле «логи» направляют к цели в разы точнее: подсказывают, какие ошибки допущены, какие разделы подправить и к чему следует стремиться. Но обо всем по порядку – от основ к деталям.
Логи сервера: назначение и содержимое
Log-файлы – текстовые документы и таблицы, записывающие и хранящие информацию о запросах, поступающих на сайт и обрабатываемых на сервере. Статистика собирается и ведется в хронологическом порядке и необходима для протоколирования работы различных систем веб-ресурса. Попадает в log-файлы много сведений, включая действия поисковых ботов (от Google, «Яндекс»), сканирующих страницы на сайте и оставляющих следы (время, дата посещения, IP-адрес), подсказывающих вебмастеру, как в дальнейшем тратить накопившийся бюджет на продвижение ресурса, как повысить положение в выдаче и какой контент подправить для привлечения новой аудитории.
Рассмотреть следы, накопившиеся в log-файлах, вполне реально и без загрузки дополнительного программного обеспечения: достаточно разобраться в базовых операциях и действиях. Если же данных накопилось слишком много для ручной обработки, то делегировать часть обязанностей по анализу продуктивнее специальным инструментам вроде Log File Analyzer.
Как просмотреть информацию в log-файле
Польза от просмотра содержимого файлов журнала очевидна – помощь в поиске проблемных мест сайта, ошибок или технических неполадок, влияющих на продвижение. Но как приступить к анализу содержимого? Пора разобраться в деталях.
Смена расширения
Записывается информация в журнал с расширением .log (отсюда и название – log-файл). Просмотреть содержимое вручную в 99% случаев невозможно – на компьютерах с MacOS или Windows едва ли найдется подходящее программное обеспечение. А потому предстоит воспользоваться распространенным трюком – сменить расширение с .log на .csv, с которым справится Excel или иные офисные программы не от Microsoft.
Как открыть сразу несколько «логов»
Действия поисковых роботов редко записываются в единый log-файл: часто сервер подготавливает раздельные каталоги, куда выгружается найденная информация (сценарий с разделением полезен для сбалансирования нагрузки, экономии трафика). Но работать с отдельными элементами не слишком комфортно – приходится вечно переключаться между журналами, проводить повторный анализ. А потому намного продуктивнее объединить логи вместе.
Сценарий действий следующий: найти каталог с лог-файлами, зажать SHIFT и правой кнопкой мыши вызвать контекстное меню. В появившемся списке выбрать пункт «Открыть командную строку», а затем – добавить команду copy *.log mylogfiles.csv. На MacOS процедура иная: понадобится cd command, а после команда cat *.log > mylogfiles.csv.
Если возиться с командной строкой некогда, то с объединением журналов справляется Log File Analyzer: специальный инструмент вызывается из главного меню, экономит время, разрешает сразу приступить к анализу содержимого.
Разделение строк
Несмотря на наличие логичной структуры в файлах журналов, периодически некоторые данные сливаются вместе. Проблема распространенная, но вполне решаемая: достаточно воспользоваться парочкой функций из того же Excel:
- Открыть раздел «Данные», выбрать в появившемся списке с действиями пункт «Текст в столбец». Офисная программа сразу предложит выбрать способ разделения данных. Подойдет пробел.
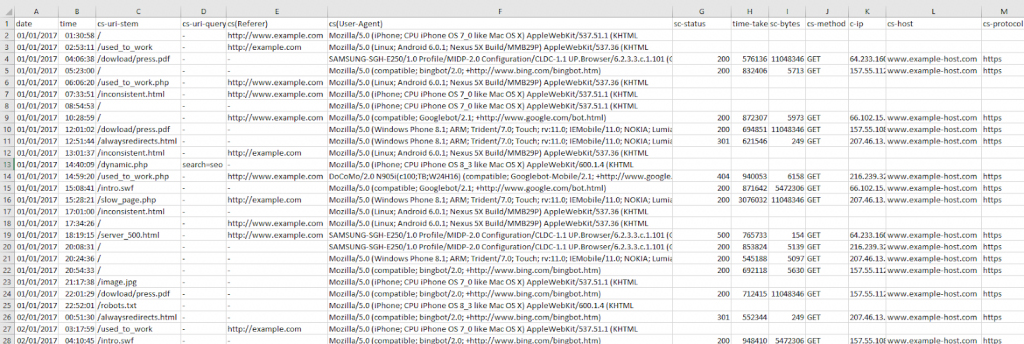
- Следующий шаг – сортировка записей по времени или дате. После нескольких экспериментов данные примут читабельную форму, выстроятся в столбцы и строки.
Как ориентироваться по log-файлу
После приведения данных к табличному виду проблем с просмотром статистики уже не возникнет. Но до исследования деталей не помешает расшифровать распространенные показатели и параметры:
- IP сервера (базовая информация о поисковом роботе);
- Дата и время посещения сайта;
- Тип запросов – Get или Post;
- Запрашиваемый URL с точными данными о ссылках;
- Статус кода HTTP, включая ошибки;
- User-Agent.
Предусмотрена сторонняя информация, которую не расшифровать вручную без использования тематических сервисов и инструментов, вроде:
- WC3.
- Apache, NGINX.
- Proxy.
- JSON.
Лимиты поисковых роботов
Рассматривать каждый из параметров в индивидуальном порядке слишком долго и не продуктивно. Намного важнее сосредоточиться на наиболее распространенных для сайтов и вебмастеров терминах. Речь преимущественно о «бюджете на обход» – количестве страниц, рассматриваемых поисковым роботом при каждом взаимодействии с сайтом (сканирование, исследование, тестирование). На конечное число посещений влияет десятки параметров: равенство ссылок, авторитетность домена, скорость загрузки веб-страниц.
Как результат – вебмастерам полезно разобраться в том, каков «бюджет на обход у сайта», какие места не помешает подправить и почему у поисковых роботов периодически возникают проблемы с доступом к отдельным веб-страницам. Дополнительно не помешает предоставить системам сканирования сайта возможность не размениваться по пустякам (не замечать лишние разделы или незначимые материалы) и сосредоточиться исключительно на приоритетных вещах и деталях. Как обеспечить бюджет на обход – подробности ниже.
Поиск страниц, сканируемых роботами, через User Agent
Начинать специалисты рекомендуют с просмотра URL, просматриваемых или сканируемых ботами чаще остальных. Из-за некорректно расставленных приоритетов велика вероятность растерять заложенный бюджет на обход и столкнуться с непредвиденными ситуациями, вроде потери позиций в органической выдаче. Исправлять ситуацию предстоит следующим образом:
- Вынос найденных логов в формат WC3, фильтрация поля CS (User-Agent), просмотр результатов;
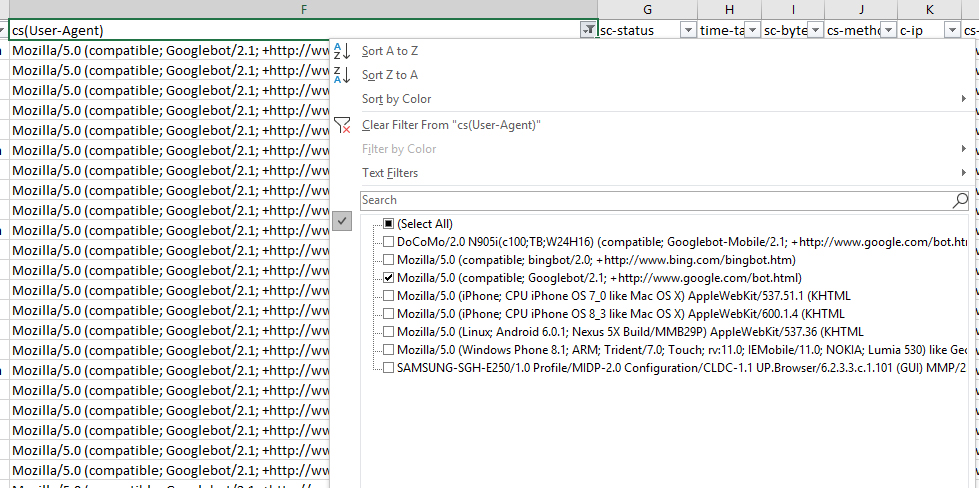
- Далее – сортировка по количеству посещений веб-страницы со стороны Googlebot (фильтрация по URI – идентификатору конкретного ресурса).
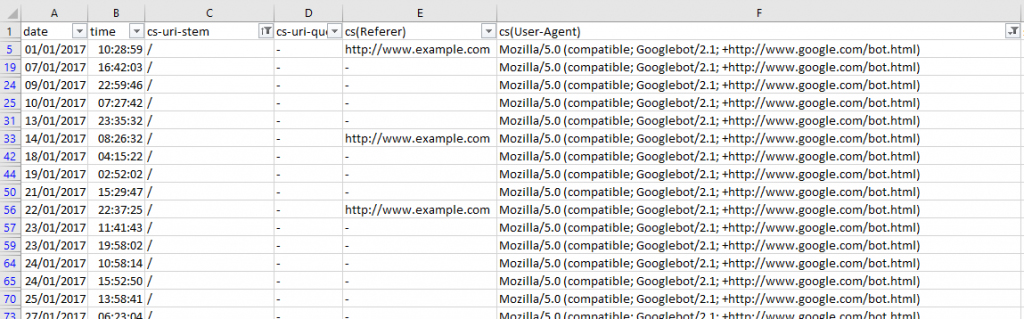
- Проверить возникают ли проблемы с User-Agent помогает столбец cs-uri-stem, предупреждающий, какие конкретные URL (в том числе ссылающиеся на медиафайлы – иллюстрации, иконки, видеоролики) подверглись обходу или столкнулись с ошибками (страницы, не нуждающиеся в индексации, недоступные разделы, неправильно расставленные приоритеты).
- Не возникнет проблем и с чуть более широким анализом с помощью сводных таблиц. Достаточно выделить столбцы со строками с указанным user-agent, а после воспользоваться фильтрацией по Count of CS.
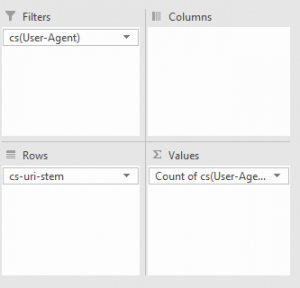
- Результаты появятся в виде списка, подсказывающее, какое количество раз то или иной вхождение встречается на сайте.
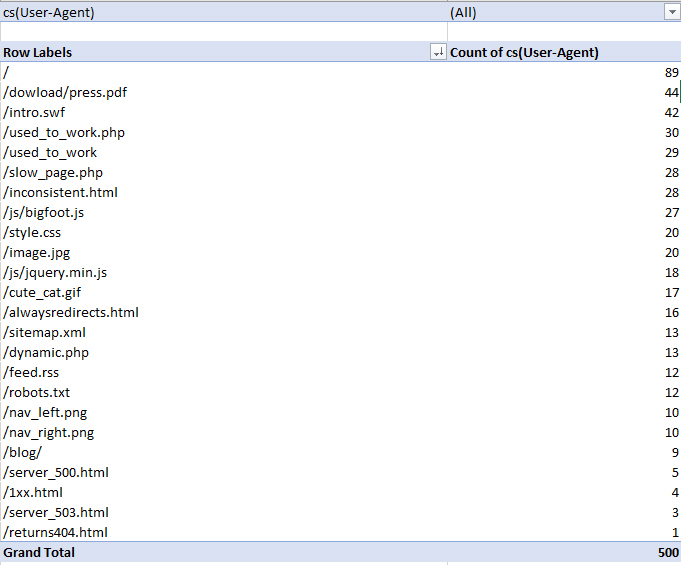
- После предварительной подготовки (фильтрации) предстоит обратиться к поисковой строке для выделения пересечений исключительно с Googlebot.
- Как действовать дальше – зависит исключительно от поставленных целей. Но пища для размышлений появится в любом случае, а вместе с тем – осознание, как расходуется бюджет на обход.
Дополнительная сортировка содержимого «логов»
Некачественные веб-страницы (промежуточные в цепочке навигации, содержащие лишь служебную информацию или необходимые для представления каталогов или разделов) незачем вверять Googlebot для обхода. Иначе бюджет начнет растрачиваться не оптимально. Намного продуктивнее найти URL-адреса, не несущие пользы, а после – исключить из индексации или привести к иному, чуть более полезному виду: дополнить материалами, разбавить медиаконтентом.
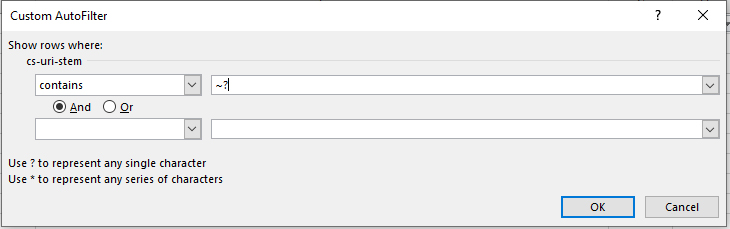
Разыскиваются страницы с низкой ценностью с помощью запроса с символом «?» в текстовом поле (если содержимое «логов» просматривается через Excel, то перед знаком вопроса понадобится еще и символ «~», добавляемый через кнопку, расположенную слева от единицы на клавиатуре). Если при поиске через таблицы от Microsoft не добавить уточнение, то офис подберет практически все значения, чем лишь запутает вебмастера.
Поиск страниц-дублей
Дубли в масштабах сканируемого поисковыми роботами сайта – бесполезная трата «бюджета на обход». Замечание вполне логичное, но исправить ситуацию намного сложнее, чем кажется. Всему виной – незначительное различие URL-адресов, а вместе и содержимого на страницах. Проблема решается сортировкой адресов по алфавиту и ручным просмотром полученных результатов (времени предстоит потратить много, но результат в 99% случаев стоит усилий). А еще предусмотрен вариант с применением функции SUBSTITUTE.
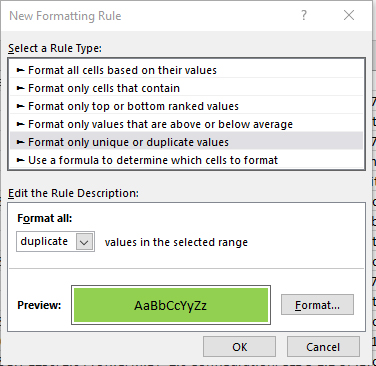
Действовать предстоит через «условное форматирование» с целевой ячейкой, указывающей на ссылки в Excel. После сортировки записи начнут выглядеть нагляднее, но просматривать результаты вновь предстоит вручную, но уже сэкономив до 15 минут собственного времени.
Как часто роботы обходят каталоги
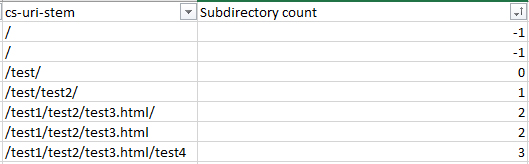
Кроме неприоритетных или бесполезных страниц бюджет на обход периодически растрачивается на количество посещений сайта. Чем чаще поисковые роботы «атакуют» сайт, тем быстрее тратится лимит. Найти информацию о том, с какой частотой боты переходят по веб-страницам вручную слишком сложно, а потому понадобится формула, представленная чуть ниже.

Перечисленная выше запись состоит из раздельных команд и предназначена для вычисления количество «слэшей» (косой черты) в URL-адресах. В результате появляется информация о поддиректориях.

Чем меньше необходимо переходить боту, тем порой лимитов на обход тратится в разы меньше, но полноценной градации порой не предусмотрено, но все же специалисты не рекомендуют слишком уж сильно вдаваться в эстетику бесконечных разделов или переходов.
Дополнительно предусмотрен вариант с анализом по типу контента: возможно, какие-то определенные материалы или медиаконтент растрачивают бюджет в разы активнее, чем даже бесконечные поддиректории. Как вариант – роботы способны по 3-5 раз сканировать схожие иконки или иллюстрации, файлы стилей CSS или JS-скрипты.
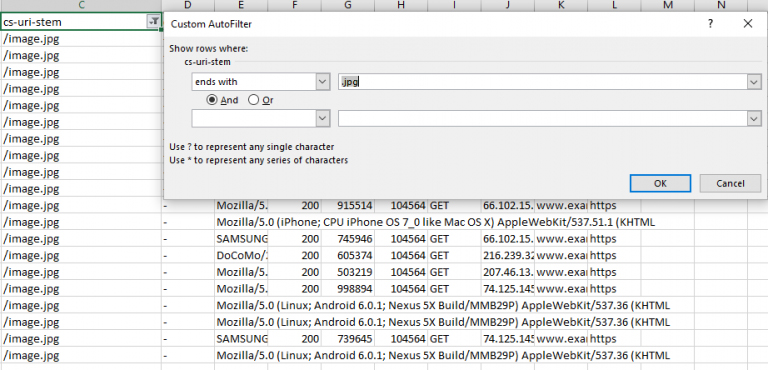
Как и в сторонних случаях подобная сортировка вполне организуема в масштабах Excel. Достаточно отсортировать информацию по формату: .jpg, .css, .js. Появившиеся результаты подскажут, какие элементы на сайте давно пора подправить.
Анализ поведения поисковых роботов
Следующий важный шаг – поиск неточностей, странностей или закономерностей в действиях ботов. Собранная информация облегчит понимание сценариев SEO, а заодно подскажет, как добиться эффективного продвижения (или хотя бы найти причину нелогичного ранжирования).
Игнорируемые URL
Кроме страниц, не несущих очевидной пользы, сортировка по значению user-agent способна рассказать, какие URL-адреса игнорируются при посещении сайта с завидной регулярностью.
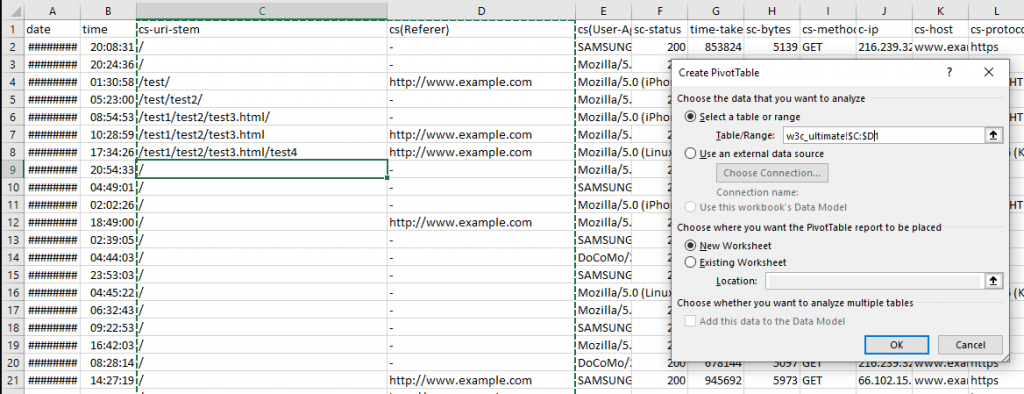
Фильтрация происходит через раздел «Вставить», пункт «Сводная таблица» в контекстном меню, вызываемом при клике правой кнопкой мыши по ячейки. Выделять рекомендуется лишь столбы с URL и URI. Дальше необходимо выбрать значение Count of CS, а после отсортировать по количеству обходов.

Проблемные места появятся в виде списка с точностью до последнего пункта.
Частотность сканирования: за день, неделю или месяц
Кроме количества важно помнить о качестве: инструментов для отслеживания действий роботов предостаточно – в особенности, если таблицы в Excel упорядочена. То дальше останется лишь ввести запрос Date, а после – выбрать, за какие конкретные дни сайт сталкивался с действиями ботов.
Обход страниц в зависимости от внутренних ссылок
Не менее полезный анализ «бюджета на обход» связан с просмотром структуры внутренних ссылок. Цель – распознать, какое количество URL-адресов в принципе представлено на сайте. Подбирать результаты намного проще с помощью сторонних инструментов, вроде ScreamingFrog.
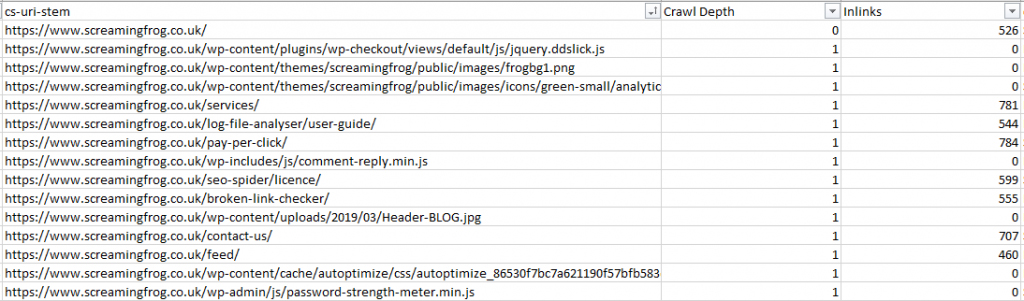
Сервис мгновенно расскажет о том, какая глубина обхода, сколько ссылок встретилось системе, какой медиаконтент проанализирован или отсканирован.
Проблемы со сканированием
Если «бюджет на обход» уже просмотрен с различных сторон, то финальный аккорд – поиск проблем, ошибок или странностей, влияющих на взаимодействие роботов с сайтом.
Ошибки обхода
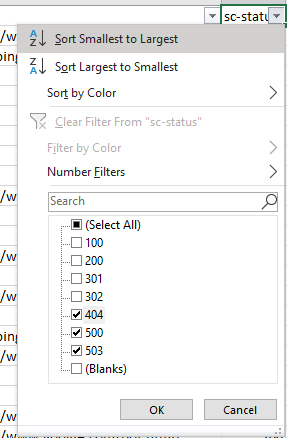
Очевидная, практически молниеносная и лишенная проблем проверка. Действовать предстоит следующим образом – вызвать сортировку по столбцу состояния (sc-status), а затем посмотреть, какие страницы сталкиваются с ошибками сервера формата 4XX
Поиск противоречий
Отсортированные URL-адреса периодически принимают разные коды сервера за пару часов. Воспринимать подобные сигналы необходимо с долей настороженности: возможно, нерабочая ссылка исправлена, и поисковые роботы заметили перемены, но порой новые ошибки намекают на проблемы с сервером. Разобраться в деталях рекомендуется сразу, иначе возникнут проблемы с дополнительной нагрузкой по трафику.
Ошибки в директориях и по user-agent
Проблемные подкаталоги на сайте подмечаются в логах с помощью столбца URI (cs-uri-stem), который содержит конкретные каталоги (запрос /blog/*). После проведения анализа система найдет проблемные места и отобразит в виде списка с дополнительными подробностями (дата, время).
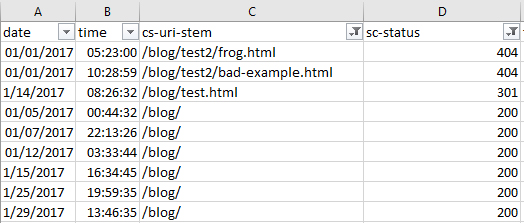
Производительность же сайта (скорость загрузки страниц, отображение интерфейса) повышается методом поиска неполадок у поисковых роботов при сканировании сайта. Если Googlebot сталкивается с ошибкой 404 (страница не найдена), то почему бы не посмотреть, как часто возникают проблемы и в каком месте.
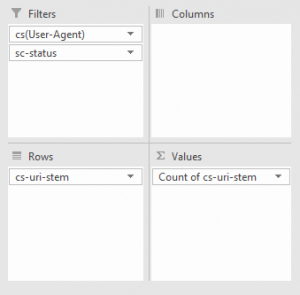
Вновь понадобится фильтрация по Values, параметр Count of cs-uri-stem. Далее достаточно выбрать, какого бота проверять (как вариант – Googlebot), а после – по какой ошибке URL (404, 200, 301).
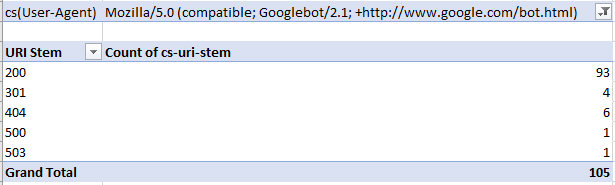
Результаты отображаются в виде списка с возможностью дальнейшей расшифровки. Справа появится информация о количестве ошибок. А чуть ниже – дополнительные подробности.
Поиск проблем на веб-страницах
Сайты привычно адаптируются под запросы пользователей: снабжаются полезными материалами, медиаконтентом, ссылками и прочей информацией, способной пригодится гостям и завсегдатаям. Но вебмастера часто забывают об обратной стороне медали: поисковых роботах, оценивающих техническую часть каждого веб-ресурса. Речь преимущественно о скорости загрузки страниц. Если каждая статья появляется на вкладке в браузере с задержкой в 5-6 секунд, то едва ли Googlebot похвалит за проделанную работу. Совсем наоборот – порекомендует незамедлительно приступить к оптимизации. Но перед началом всех действий необходимо заглянуть в файлы и определить, какие страницы загружаются слишком медленно.
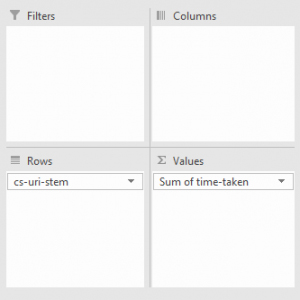
Вновь потребуется сводная таблица, со строками URI, значением – Sum of Time Taken (время, потраченное на появлением материала).
После предварительной подготовки у поля Sum Of Time Taken необходимо вызвать контекстное меню (правой кнопкой мыши), а после выбрать параметр Value Field Settings. Среди предлагаемых значений на вкладке Summarize Values By достаточно выбрать вариант Average (средний).
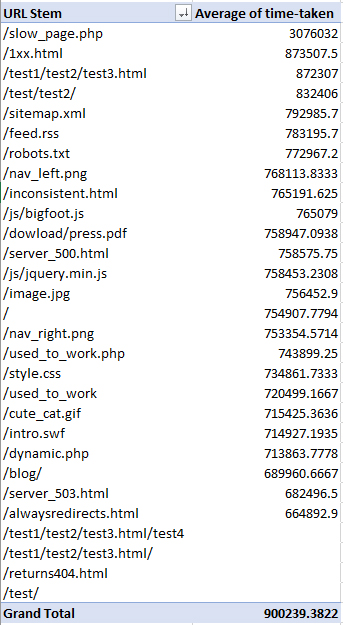
Система мгновенно отфильтрует информацию в логах, а после отобразит, какие страницы загружаются слишком долго.

Дополнительно специалисты рекомендуют добавить еще и Average of SC-Bytes в метод сортировки (вновь со значением Average). В результате появится дополнительная колонка, отображающая объемные страницы, то есть, содержащие лишний контент – иллюстрации, таблицы, иконки, подгружаемые из сторонних источников. Если суть статьи после избавления от части графических элементов не поменяется, то лишние детали не помешает скрыть.
Вердикт
Проводить анализ действий поисковых роботов полезно и вручную, и с помощью сторонних инструментов: вебмастера, разобравшиеся в том, как сканируются веб-страницы и какие показатели влияют на ранжирование, способны в кратчайшие сроки добиться повышения позиций продвигаемого сайта в органической выдаче.